SMS-phishing (coined "smishing") is a class of
social engineering attacks that exploit mobile
users. Despite advances in detection systems,
various detection systems today lack adversarial robustness and rely on quickly outdated
datasets. To proactively detect weaknesses in
modern smishing detection software, we leveraged the classification explanations produced
by smishing detection system SmishX to
adversarially fine-tune an LLM capable of generat-
ing evasive smishing messages. Unlike prior
adversarial phishing generation methods that
rely on heuristic perturbations like character
obfuscation and synonym replacement, our approach conditioned generation on the detector’s
own explanations and classifications, enabling
explanation-guided adaptive attack refinement
under a black-box threat model. For comparison, we fine-tuned the Qwen2.5-7B-Instruct
under three different scenarios: no explanations, perturbation suggestions, and the SmishX
explanations. While all three methods were
capable of producing some messages that bypassed detection, the SmishX explanations did
not prove to be the vulnerability that we had
originally feared.
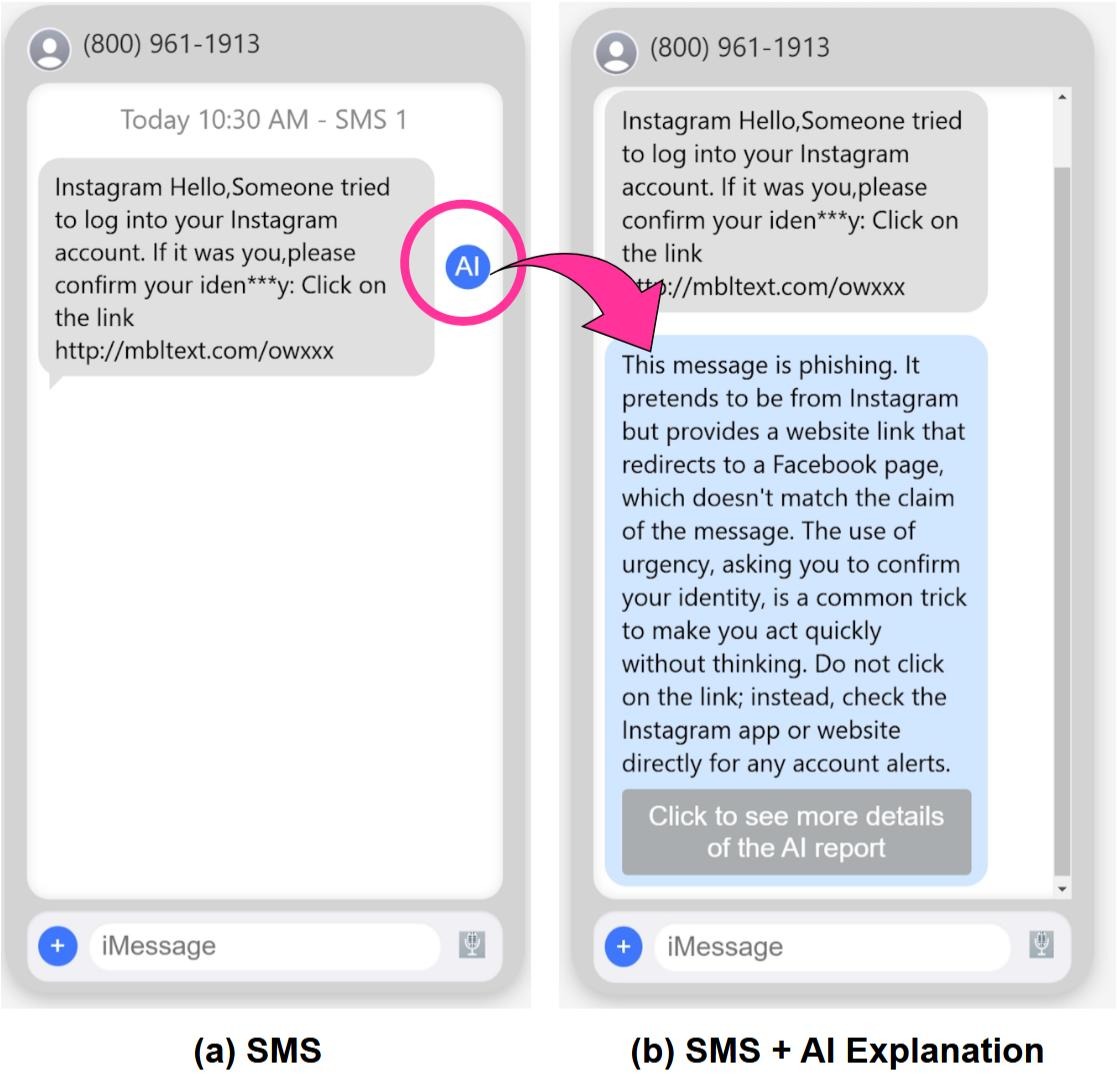
An example from the 2025 Wang et al. paper of their SmishX system's explanation to the user about a
suspicious SMS message.
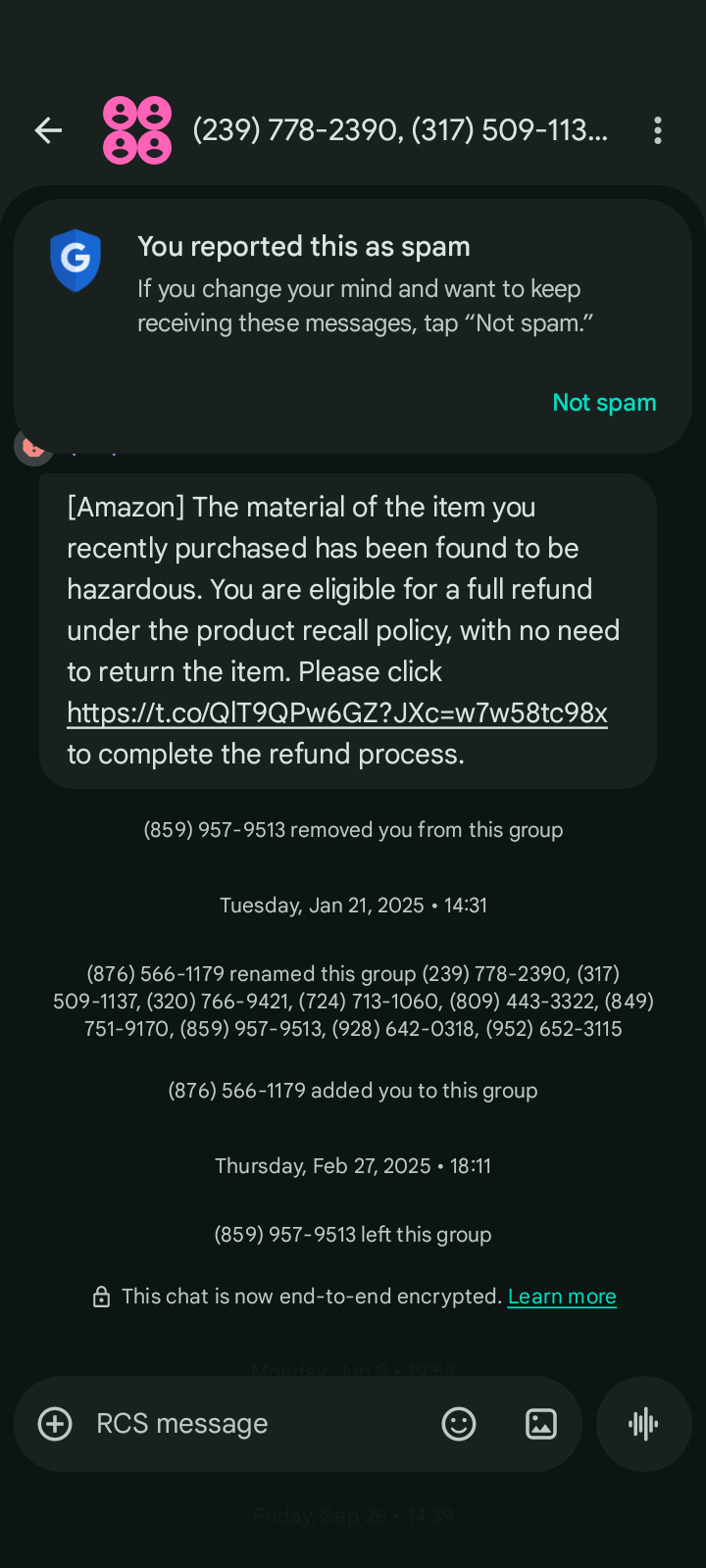
An example smishing message showing the common use of popular brands and shortened links.
Introduction / Background / Motivation
Introduction
SMS phishing, also called “smishing,” is a rising
tactic by malicious attackers to fool mobile users
into revealing sensitive data and credentials (Aspen
FSP). 68% of adults report receiving phishing SMS
messages weekly or daily (Aspen FSP). Falling
for smishing can lead to financial fraud, identity
theft, malware, and many other detriments (Aspen
FSP). Therefore, research in this area focuses on
developing systems to detect smishing messages
to help protect mobile users, especially the older
population who are especially vulnerable to such
attacks (Wang et al., 2025).
The SMS domain is especially difficult to
prevent phishing due to the brevity of an SMS
message, the prevalence of link shorteners, lack
of real-time SMS phishing data, and a higher
level of trust users place in SMS as compared
to email (Wang et al., 2025). Users struggle
with discerning phishing from legitimate SMS
messages, and malicious actors are continually exploiting new ways to fool users (Wang et al., 2025).
One of the ways a recent paper seeks to
address the challenge posed by users’ lack of
discernment is by building SmishX, a system
of Large Language Model (LLM) agents that
breaks the problem of detecting smishing into
subtasks, including generating a user-friendly
explanation of the SMS classification (Wang et al.,
2025). One LLM agent extracts information
from the SMS message and uses data mining
techniques to augment the context of the message
(Wang et al., 2025). A second agent classifies the
message as legitimate, spam, or phishing (phishing
messages are actively deceptive and attempt to
steal information from the user, while spam is
general unwanted advertising) (Wang et al., 2025).
Finally, a third LLM crafts an explanation for the
user for why the message was flagged as spam or
phishing (Wang et al., 2025).
The authors hypothesized that explanations
would a) teach users how to identify smishing
and b) help prevent users from falling for the
smishing attack (Wang et al., 2025). The SmishX
system had an accuracy near 100% on classifying
phishing messages and 99.1% for spam messages
(Wang et al., 2025). Their user studies also found
that users greatly benefited from reading the AI
explanations, as the explanation improved their
phishing detection accuracy across all age groups
(Wang et al., 2025).
The SmishX system was a powerful advancement in smishing detection and the explanations
have great potential to help users decipher messages they receive on their mobile devices. However, we were
concerned that these explanations
may open a door to helping malicious actors improve their attacks, continuing the never-ending
cycle of attack and defensive reaction to improve
detection systems. Therefore, our project aims to
investigate explanation-driven adversarial training
on the SmishX system to proactively expose vulnerabilities rather than reactively to current attacks. This work
could help bolster current smishing detection systems developed by mobile network carriers and mobile phone
companies.
Related Work
Smishing Detection
Current smishing detection systems and research
range from analyzing IoT-based aspects such
as network traffic patterns, traditional machine
learning models such as random forest and support
vector machines on text content classification,
deep learning models such as convolutional
neural networks and transformer models, and
hybrid combination approaches (Rahaman et al.,
2025). IoT-based detection suffers from the
challenge of privacy concerns, limited computation
resources, dependence on cloud processing, and
interoperability issues across a variety of platforms,
while basic machine learning models like random
forest have a high false positive rate and have
difficulty adjusting to sophisticated smishing
attacks (Rahaman et al., 2025). Deep learning
models suffer from the challenge of high data and
hardware requirements during training (Rahaman
et al., 2025). Scarcity of information also proves
to be a challenge in smishing detection. Some
research in this area combats the scarcity with data
mining to extract more information, such as the
URL destination HTML content, pulling brand
information, and more to obtain more context for
the SMS message (Karhani et al., 2023).
In the specific usage of LLMs to detect phishing,
researchers have experimented with three main
categories of LLM learning methods: zero-shot
and few-shot learning, chain-of-thought prompting,
and fine-tuning (Salman et al., 2025). Zero-shot
learning provides a task description and the label
space to the model, while few-shot learning gives
the model a few examples. Chain-of-thought
prompting, which is what SmishX leverages,
breaks a task into smaller steps for the model to
reason through. Fine-tuning usually starts with
an initial pretrained model and modifies a set
of new weights to fine-tune the model for the
task. Zero-shot learning performs unreliably in
generalized situations, and few-shot, while it can
improve detection, suffers from variability across
models (Salman et al., 2025). Chain-of-thought
prompting performance is dependent on the LLM
agent, while fine-tuning achieves the highest
accuracy in detecting smishing, but suffers from
longer training (Salman et al., 2025).
Researchers have identified many classes of
smishing attacks, such as social engineering or
URL masking attacks, but malicious actors have
continually found new ways to exploit mobile users
(Rahaman et al., 2025). Despite the advancements
in phishing detection, the detection systems lack
real-time data (Rahaman et al., 2025), which pre-
vents them from quickly adapting to new attack
techniques. They also suffer from a lack of robustness to adversarial attacks, which puts them in a
vulnerable position to malicious actors (Rahaman
et al., 2025).
Smishing Adversarial Training
Various adversarial attack methods have been
discussed in the literature. In the development of
the SpaLLM-Guard phishing detection system,
the authors incorporated black-box adversarial
training, which assumes that the attacker does
not have access to the internal workings of the
phishing detection system such as parameters
and weights (Salman et al., 2025). This is a
reasonable assumption to make, as the inner
workings of a commercial phishing detection
system would likely be proprietary knowledge. For
this reason, in our adversarial message generation
system, the model will only have access to the
user-facing outputs of SmishX, which are the
overall classification and the LLM’s reasoning.
The authors of the SpaLLM-Guard paper had
9 specific attacks that they used. These attacks
include human-visible attacks such as inserting or
deleting random characters in SMS messages, and
they include non-visible attacks such as inserting
zero-width spaces and similar appearance character
substitution. (Salman et al., 2025).
Hasan et al. acknowledge that with the current
state of LLMs, they can be used for both phishing
detection and the generation of phishing attacks.
They focused their attention on email phishing attacks.
They experimented with various forms of adversarial attacks when creating their LLM-PEA system, which is a
system that evaluates other LLMs
on their vulnerability to email phishing attacks. Although they were focusing on email attacks, and we
are focusing on SMS attacks, some of their ideas
are transferable. They experimented with prompt
injection within messages, multilingual messages,
and encoding artifacts (Hasan et al., 2025). These
are all methods that we can experiment with when
testing against SmishX.
Vinod et al. focused their research solely on using prompt engineering with various language models to generate
adversarial smishing messages that
could bypass smish detectors. They discovered that
certain prompt engineering techniques had high
success rates in accomplishing such a task. In particular, Auto-CoT and Persona prompt engineering
techniques proved especially effective in this task.
These more complicated prompting techniques encourage the agent to emulate real entities like banks
or payment services. The messages generated via
the Persona prompting technique tended to be more
plausible to humans, and the messages generated
with the Auto-CoT method tended to convey more
urgency, which sheds light on vulnerabilities of
current smishing detection systems (R et al., 2025).
Novelty
As seen in the prior section, both prompt-engineering and LLM fine-tuning have been used
for generating adversarial phish messages. However, we were aiming to take a new approach by
incorporating feedback from the SmishX smish
detection system into a reinforcement learning approach. Unlike current adversarial training using
just character perturbation and synonym replacement to attack detection systems, we attempted to
exploit the reasoning for the smishing classification to provide guided adaptive refinement across
iterations. By leveraging the initial SmishX classifications and explanations on smishing messages,
our system attempts to alter the given smishing
message to bypass SmishX, while still maintaining
its validity as a smishing message (for example, by
rendering the message harmless by removing all
URLs). Analyzing the adaptation patterns across
multiple messages can ultimately determine the
vulnerabilities of the SmishX system. Our goal
was to investigate the potential of the Qwen2.5-7B-Instruct LLM to learn via fine-tuning and reinforcement
training techniques to augment the smishing
messages on its own to identify vulnerabilities in
smish detection systems. We experimented with
different prompting strategies that provided more
or less information about phishing techniques, as
well as including or not including the SmishX user-friendly explanations.
Approach
Experiment Setup
SmishX Baseline Experimentation
The first step necessary to our experiment was getting the baseline SmishX detection system running
on our machines. The original SmishX system relied on the GPT-4o model. However, the cost of the
GPT-4o model would have been cost-prohibitive,
given that it costs $2.50 per million input tokens
and $10 per million output tokens (OpenAI, 2026).
As an alternative, we decided to attempt running
the SmishX detection system with the GPT-4o-mini
model. The mini model only costs $0.15 per million input tokens and $0.60 per million output tokens, making it
much more reasonable (OpenAI,
2026).
Given that we were switching models from the
initial SmishX system, we needed to establish a
new accuracy baseline. This was also important
because it had been a year since the original dataset
had been run through the SmishX system, and the
url validity and brand statuses in the messages may
have changed, which would affect the results. We
took the 1200 messages in the original SmishX
dataset and ran it through the SmishX system altered to use GPT-4o-mini. Out of the 1200 messages, 1128 were
accurately classified, making for
a 94% accuracy rate. We decided this was sufficiently high and decided to proceed with using the
GPT-4o-mini model.
Message Filtering
Smishing messages typically rely on having valid,
reachable websites. However, these fraudulent
websites can set up and taken down frequently.
This caused a large amount of the messages in our
dataset have invalid URLs. This essentially renders
the message harmless and would affect the SmishX
detection output. Due to this, we decided to filter
out any messages that resulted in a 4xx or 5xx error
when attempting to reach them. Additionally, we
filtered out messages that returned 200 statuses, but
the GPT-4o-mini analysis determined contained a
404 Not Found message on the website.
We collected smishing messages from five different sources. The first source was the original
SmishX dataset. The second was the SMS Spam
Collection dataset from the UC Irvine Machine
Learning Repository. This dataset contains 5,574
SMS messages, which are a mix of spam and legitimate messages (Almeida and Hidalgo, 2011).
We also utilized the SMS Phishing Dataset for
Machine Learning and Pattern Recognition from
Mendeley Data. This dataset is made up of a combination of smishing, spam, and legitimate SMS
messages. It has 5,971 messages in all (Mishra
and Soni, 2022). To further supplement our dataset,
we utilized smishing messages from Smishtank.
Smishtank is a crowd-sourced SMS message collection (Timko and Rahman, 2024). Lastly, we
collected a sampling of smishing messages from
friends and family.
Since the goal of this project was to get smishing
messages to bypass the SmishX system, we filtered
out all of the legitimate SMS messages from our
dataset so that we had only spam and smishing messages left to run through our fine-tuning system.
URL Analysis Caching
One major limitation we encountered was the
length of time it took to run a message through
the SmishX detection system. Depending on the
number of URLs and brands in the message, the
system took from 20 seconds to one minute for
a single message analysis. Considering that we
wanted to be able to get the SmishX detection outputs in real-time in our fine-tuning model system,
we knew this runtime would not be feasible. We
added timings to the SmishX system and determined that the largest portion of time was being
spent on url analysis.
Considering that we were just going to reuse the
valid URLs and only alter the wording around the
URLs, we decided to cache the url analysis results.
After parsing out the valid URLs from the dataset,
we ran those messages through just the url analysis
portion of the SmishX detection system and saved
the GPT-4o-mini generated analysis for each url.
This allowed us to just load the cache of URLs
from the saved file on model start-up and retrieve
the url analysis at runtime.
Fine-tuning for Adversarial Generation
We used Qwen2.5-7B-Instruct for our adversarial
model. The model has 7 billion parameters, similar
in size to the estimated parameter size of GPT-4o-mini, which was important to ensure equality
in the parameter size class between the SmishX
model and adversarial model for fair training. We
experimented with several other models, such as
the mistralai/Ministral-3-8B-Instruct-2512, but we
struggled to get consistent output for generating
smishing messages, and Qwen2.5 had the most
consistent structured output for messages.
We fine-tuned the model with LoRA, freezing
87% of the parameters and training 13% of the
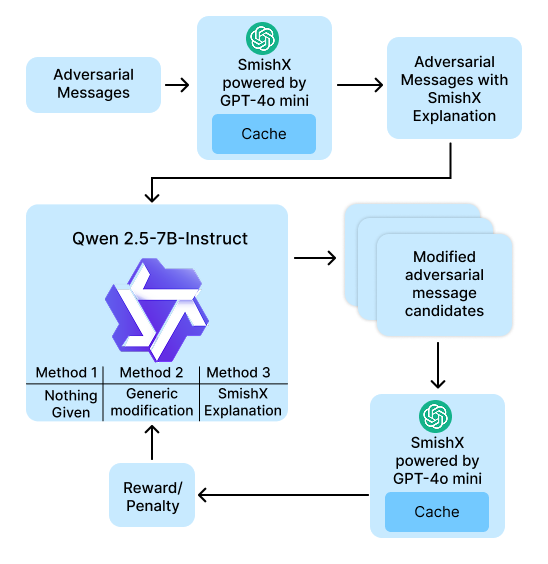
parameters. As shown in Figure 1, we set up a reinforcement learning framework, where the training
loop generated 5 candidate messages. As recommended by the Qwen developers, we generated the
5 candidates in one generation to increase the diversity between messages. We added post-generation
processing to ensure links were the valid links from
the original message. We then ran the candidates
through SmishX, utilizing the cache to speed up
training. The reinforcement learning feedback penalized adding a link or removing a link, while
rewarding candidates being marked as legitimate
by SmishX.
Figure 1: Diagram of the experimental setup of the adversarial model with reinforcement learning via
SmishX.
Hypothesis and Methods
We hypothesized the SmishX explanations could be exploited to adversarially train the Qwen model
to generate messages that deceived SmishX according to what flagged as suspicious. However, to
test this, we also trained the Qwen model on other
prompt methods to see if the SmishX explanations
impacted the performance, or if it was just the adversarial training that impacted the attack success
rate. For all our methods, we gave it a system
prompt of not removing, adding, or modifying any
links. We trained and tested 3 different methods:
For our baseline method, we gave Qwen the instructions to modify the message to deceive the SMS
phishing detector and just the message. For the
next method, we gave Qwen suggestions of how
to modify the message, such as removing urgency,
adding a professional tone and company brand-
ing, adding opt-out wording, making the message
sound like the user has interacted previously, and
making the message sound like a service notification. Finally, for our main experimental method,
we gave Qwen the SmishX explanation along with
the message and instructed it to use the explanation
to modify the message. Our hypothesis was that
the model would have the best attack success rate
(ASR) with the SmishX explanation method since
it would have a guided approach to modifying the
message tailored to each message. We postulated
that the next most successful method would be the
modification strategies method since it would have
general strategies that could improve the ASR, and
we predicted the model would perform the worst
on the nothing method.
Challenges
One of the largest challenges we faced in this experiment was lack of high quality data. The existing
datasets for SMS messages were outdated, so the
majority of the links in the SMS messages were
expired, taken down, or invalid. The lack of recent
data is a large hindrance in any smishing detection
research. We were able to find several datasets and
source smishing messages from people we know,
which combined gave us enough to train our adversarial model on a small dataset of 270 phishing
messages.
We also ran into rate-limiting issues when running our model, and had to postpone our model
training while waiting for the GPT-4o-mini rate-limiting cool-down.
Another challenge we ran into was the long training times for our model. With our dataset, it took
around 20 hours to train each model. We also ran
into issues with our model crashing from lack of
memory, so we saved our model’s training and parameter state after each epoch to be able to pick
back up training from the epoch instead of starting over. We also addressed this by switching to
running the training code on Google Colab’s A100
High-RAM GPUs.
Results
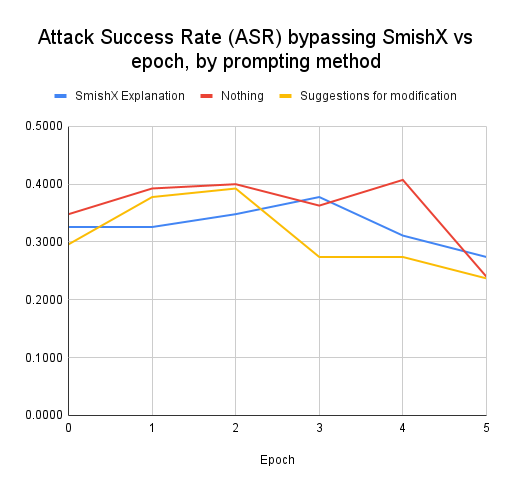
We evaluated the adversarial model on the attack
success rate (ASR) of each method over its training.
The results are shown in Figure 2. As can be seen
in the chart, the nothing method had on average the
best ASR, with the SmishX explanation method
and the nothing method being more difficult to
differentiate.
Figure 2: Attack Success Rate (ASR) bypassing SmishX vs epoch, by prompting method
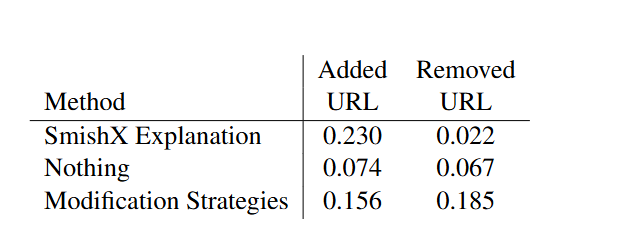
We also tracked the rate of adding and removing
links in the message, with the results shown in
Table 1. The SmishX explanation method had the
highest rate of adding URLs. However, it also had
the lowest rate of removing links. Nothing method
had a low rate of adding or removing links, while
modification strategies method had a somewhat
higher average rate of adding or removing links.
Table 1: Frequency of adding URLs and removing URLs by adversarial method.
Discussion
Quantitative Analysis
Our hypothesis was the SmishX explanations could
be a vulnerability in the state-of-the-art smishing
detection systems. However, Figure 2 surprisingly
indicates the nothing method performed overall the
best. The modification strategy performed stronger
in the initial epochs than the SmishX explanation
method, but later fell short of the SmishX explanation method. All three methods were relatively similar in
their attack success rate, which suggests the
SmishX explanations are not as much of a vulnerability as initially hypothesized. It performed comparably to the
modification strategies, and its best
ASR of 0.378 still did not best nothing method’s
best ASR of 0.407.
Potential explanations for these surprising results include the nothing prompt finding more creative and
effective ways to bypass SmishX rather
than just doing the opposite of the smishing classification explanation. Additionally, the SmishX
explanation could have similar feedback to the modification suggestions, which could account for the
similarity between the SmishX explanation performance and suggestions for modification method
performance.
However, to investigate the results, we performed qualitative analysis on the generated messages from each
method. We examined the difference between the original message and candidate
message to see how the adversarial model modified
the message.
Qualitative Analysis
SmishX Explanation Method
For the SmishX explanation method, the adversarial model followed the instructions according to the
explanation in most of the messages. It removed
urgency, replaced threatening tones with calm and
kind tones, and reworded messages to have proper
English. It also removed enticing clickbait, for example, the message “"Michael, how is it hanging?
Check out this unbelievable video t.co/XXXXXXX
before it got taken down by authorities. You probably can guess now who 00:41” had SmishX explanation “This
message seems suspicious. It uses
urgency to make you want to click on a link and
talk about an unbelievable video, which is often a
tactic used in scams. Additionally, the link goes to
a site that promotes programs for attracting women,
which indicates that it’s likely just spam and not
a legitimate message. It’s best to avoid clicking
on the link or responding to the message.”. The
model removed the clickbait portion by rewording the message to “Michael, how is it hanging? I
found this interesting video t.co/XXXXXXX that I
thought you might enjoy. You probably can guess
now who 00:41”, which bypassed SmishX.
Furthermore, upon inspection of the SmishX explanations, the messages that did not contain a link
or branding information flagged as lacking identifying context that contributed to smishing suspicion.
Thus, the adversarial model seemed to compensate
for the lack of identifying information by adding a
link despite being instructed not to add or remove
links. The model did have a great rate of not removing links, with only 2% of the generated messages
removing links.
Modification Strategies Method
The modification strategies method had a high
ASR, however, on inspection of the messages that
bypassed SmishX, we realized some of the messages degenerated into short SMS message unrelated to the original
message. For example, “Please
give us a call at 855-510-1666 asap. We can offer savings on the matter you have in our office.”
turned into “[Company Name] Team”, and “Jun
18, 2022 Dear. You are invited to join the (Bitcoin) internal discussion group Reply number and
click the link to join" was reworded to “Thank you
for choosing our services.“ which likely wouldn’t
result in smishing the mobile user.
Nothing Results
The nothing prompt method did surprisingly well
at identifying the suspicious aspects of the messages. It removed urgency and financial incentives,
reworded the message to have proper English, and
modify the messages to sound more like service
notifications. It came up with creative ways to
fool SmishX, such as swapping the word “payout”
with “claim” to emphasize prior interaction with
the SMS user. It reworded the messages to have
a calmer tone, removing harsh wording, such as
removing legal recourse sentences “...We’re aware
that this number is not disconnected, you’ll be fined
and sent to jail for minimum 6 years if no reply.”
to “...We understand your concerns, and we are
here to help. No action is required unless you wish
to attend our informational meeting. No fine or
legal action will be taken without your participation.” Questions arise with this type of modification: would it
still phish users? Or would it render
the message less effective in phishing users?
Error Analysis
Modification Strategies Method
The modification strategies method suffered from
using generic example names in rewording the
smishing message, such as using “XYZ Company“
or “[Company Name]” instead of a specific company name. Using these obviously generic names
tipped off SmishX to the smishing, as it would lack
identifying information or fail the brand search.
This is a limitation of the method in generating
realistic messages, especially as it would likely fail
to entice a user to click on the message when they
saw generic names. This error could potentially be fixed by instructing the model to identify brands to spoof.
Nothing Method
The nothing method suffered from adding and removing links similar to the other methods. It struggled with
well-known brands not fooling SmishX,
and it sometimes didn’t modify the message much
from the original message, so it still flagged as
smishing. Additionally, the nothing method would
identify issues such as urgency, in the message as
being suspicious, but it would only slightly modify the messages to remove urgency, and wouldn’t
eliminate all of the urgency or threatening tone, so
it still flagged as smishing.
SmishX Explanation Method
The main error the SmishX explanation method
suffered from was lack of full understanding all the
suspicious aspects of the malicious message. The
adversarial model with the SmishX explanation
method used the explanation to modify relevant
aspects of the message. However, the explanation
often only revealed a partial view of what flagged in
the message. For example, the message “ (CA) Grocery BFT#568008: Receive your assigned $289.00
now. Type ’A’ to transmit your grocery bonus to
your selected institution.” was classified as smishing with explanation “This message is likely a
phishing attempt. It talks about receiving a grocery bonus of $289, which is a common trick used
to get people excited and trick them into responding. The urgent request to "Type A" feels suspicious and
suggests it could be trying to collect your
personal information, so it’s best not to reply or
share any details.” The adversarial model modified
the message to be “(CA) Grocery BFT#568008:
Received your assigned amount. Please visit our
website for more details. A Text Message : D”, following the SmishX explanation by removing monetary amounts and
“Type A.” However, running
the modified message through SmishX revealed
more suspicious aspects of the message, with the
explanation “The message you received seems a
bit suspicious. It talks about an "assigned amount"
and asks you to visit a website for more information, but it doesn’t clearly say who it is from or
provide a real source. Since the language is vague
and it lacks details about the sender, it’s best to
be cautious and not respond or share any personal
information.” This shortcoming reveals a strength
of the SmishX system in that it doesn’t reveal all
of the decisions used in the classification decision,
which helps prevent bad actors from one-shotting
their messages with the SmishX explanation.
Additionally, the SmishX explanation method
also suffered from removing so many specific details from the smishing message that the message
was flagged as unclear and suspicious. For example, a bitcoin smishing message to join a group chat
“Dear. You are invited to join the (Bitcoin) internal
discussion group. Reply number and click the link
to join” was reworded to “We wanted to share some
important updates with you and have included a
link to our official blog for more details. If you
need further information, feel free to reply to this
message. We value your feedback.” SmishX found
the modified message to be too generic and lacking in identifying context, increasing its suspicion
level. Some of these errors could be remediated potentially by running the message multiple times through the
adversarial model and SmishX to iteratively refine the messages, which could potentially increase the attack
success rate.
Conclusion and Future Work
Limitations and Future Work
A large limitation with our work is the small size of our dataset.
Future work could focus on finding ways to collaborate with users and/or mobile networks to collect recent
smishing messages reported by users.
This carries privacy concerns, however, which require delicate handling to ensure privacy and consent of mobile
device users.
Additionally, the work we did would benefit from user studies to understand how well the adversarial messages
are able to fool mobile users.
This would yield insight into whether the generated messages are more or less believable than their original
form.
Ethics
Our work carries ethical concerns with focusing on adversarially training a model to fool smishing detection
systems.
Our work could potentially help malicious actors learn how to improve their attacks.
However, the goal of this study was to assist the smishing detection field in proactively identifying
smishing tactics.
We are not releasing our adversarial model to the public. Additionally, we redacted any malicious links in this
report.
By illuminating vulnerabilities in current smishing detection systems, we can facilitate awareness and action to
bolster the defense of detection systems.
Conclusion
The current smishing detection systems are very robust at identifying legitimate from smishing messages given
the current datasets.
The potential of exploiting user-friendly explanations of the classification was found to not be the
vulnerability we hypothesized.
Given the nothing method performed better than the SmishX explanations method, malicious actors have just as
much of a likelihood of generating creative messages that fool current detection systems with no additional
information than with using the smishing explanations.
Thus, our results suggest the smishing classifications explanations can be used to teach users to look out for
smishing messages and help encourage them not to click the malicious links or respond to the message.
Given the challenges we encountered with the lack of current malicious links, our work stresses the lack of high
quality, current datasets.
Future research should focus on improving the channel of obtaining high quality data, as the lack of current
data severely hinders the research in the field.
Malicious actors move swiftly with creating new malicious links, and website hosting providers take these links
down, so many links are short-lived.
Additionally, we found many phishing messages from friends and family on their mobile devices, yet these
messages are unavailable to the general research field.
Furthermore, the website SmishTank is not maintained, so it hinders the progress in publicly sourcing smishing
data.
Without high-quality data, the field lacks the information to test the robustness of current detection systems.
With more data, we could proactively identify ways malicious actors could deceive smishing detection systems.
References
Tiago Almeida and Jos Hidalgo. 2011. SMS Spam
Collection. UCI Machine Learning Repository. DOI:
https://doi.org/10.24432/C5CC84.
Hadi El Karhani, Riad Al Jamal, Yorgo Bou Samra,
Imad H. Elhajj, and Ayman Kayssi. 2023. Phishing and
smishing detection using machine learning.
In 2023 IEEE International Conference on Cyber
Security and Resilience (CSR), pages 206–211.
Sandhya Mishra and Devpriya Soni. 2022. SMS PHISHING DATASET FOR MACHINE LEARNING AND
PATTERN RECOGNITION. Mendeley Data. DOI:
doi: 10.17632/f45bkkt8pr.1.
Daniel Timko and Muhammad Lutfor Rahman. 2024.
Smishing dataset i: Phishing sms dataset from smishtank.com. pages 289–294.
Yizhu Wang, Haoyu Zhai, Chenkai Wang, Qingying
Hao, Nick A. Cohen, Roopa Foulger, Jonathan A.
Handler, and Gang Wang. 2025. Can you walk me
through it? explainable sms phishing detection using
llm-based agents. In Proceedings of the Twenty-First
USENIX Conference on Usable Privacy and Security,
SOUPS ’25, USA. USENIX Association.